

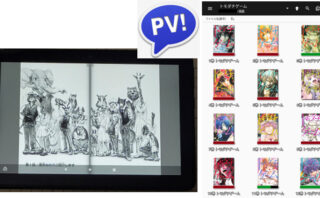








この記事では光造形等の記事とは異なり、自身が活用している書籍・漫画本の電子化、いわゆる「自炊」について、手順等を解説しております。
※本ページは下記記事からの続編となっておりますので、まだ見られていない場合は一度下の記事を御参照頂ければ幸いです)
参考記事

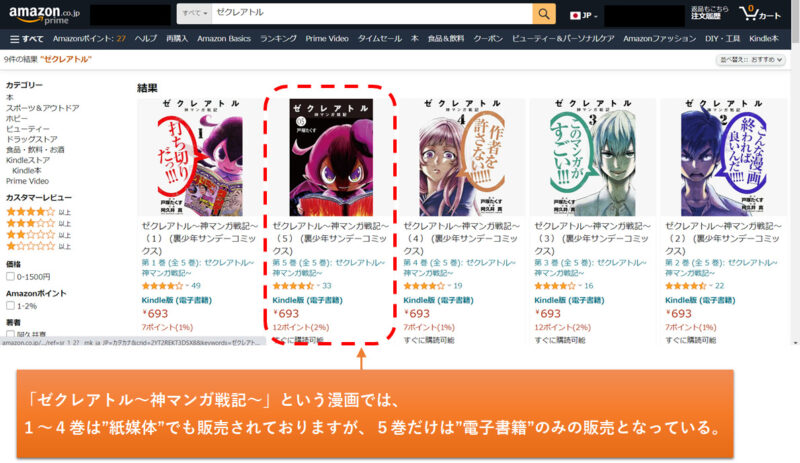
連載漫画等の中には、最初は紙媒体の単行本の販売していたのに途中から電子書籍のみの販売しかない漫画ってありますよね。
(例)裏少年サンデーコミックの「ゼクレアトル ~神マンガ戦記~」は、5巻だけ電子書籍のみの販売となっている。
紙媒体の本ではこれまで解説しました自炊方法で「PerfectViewer」で読む事が出来ますが、電子書籍版では専用のReaderアプリやツールでしか見る事が出来ず、結構不便です(; ・`д・´)。
そこで、今回は番外編として電子書籍の本も「PerfectViewer」アプリでも読めるようにする「電子書籍の自炊」で私自身が行っている方法について解説していきたいと思います。( `ー´)ノ
今回解説致します「電子書籍の自炊」の内容を簡単に紹介しますと、以下の手順内容で実施しております。
①電子書籍をwebブラウザ(GoogleChrome)で開く。 ②開いたページを「FireShot」でキャプチャし画像データで保存。一冊分行う。 ③保存した各画像データを「Jupyternotebook」(Python3)で自動でサイズ切取りを行う。 ④サイズ切取りをしたJPEGデータを画像編集・整理する。 ⑤自炊した書籍データをタブレットで読む。
上記のようになっており、紙媒体での自炊より少々手間が掛かる方法となりますが、わざわざReaderアプリを切り替えずに読む事が出来るようになります。
注意
上記の自炊内容の為、下記のような制限がありますので、注意が必要です。
・webブラウザには「Google Chrom」が必要です。 ・電子書籍は「GoogleChrom」ブラウザで見る事が出来るものに限ります。(例:Amazon Kindle 等) ・Pythonを実行する為のソフトウェア環境が必要です。私は「Jupyternotebook」を使用しておりますので、今回はそちらで解説致します。
上記ツールは基本全て無料ツールとなっておりますので、費用は掛かりません(^^♪
重要注意事項
電子書籍でも当然「著作権」が各本毎にあります。自炊には本という「著作物」を複製する行為に当たる為、個人で楽しむ以外で他人にデータを販売したり、自炊代行等でサービス販売する行為は、「著作権法違反」となってしまいますので、充分にご理解の上、行って下さい!( `ー´)ノ
・自炊作業はあくまで個人で楽しむ為の目的とし、決して自炊した書籍データの販売を目的とした行為はNG。 ・基本的には自炊代行等のサービスを販売する行為はNG。 (※実際は合法/非合法の不透明性はあるものの、過去に代行業者に向けて代行差し止めを求める訴訟が行われております。)
各項目ごとで私自身が行っている方法について解説していこうと思いますが、必要に応じてお好みで是非アレンジしながら楽しんで頂ければと思います(^^♪
それでは解説していきたいと思います。
準備
Google chrome 拡張機能ツール「Fire Shot」
上記のツールは、webページ全体のスクリーンショット、保存する為のツールです。

< スクリーンショットなんか、キーボードを押して出来るじゃないか!!( `ー´)ノ
と思われると思いますが、このツールの相性が良い所はショートカットキーが使える事にあります。漫画一冊分を各ページ開きながらスクリーンショットを行いますので、少しでも作業効率化できるツールとして今回採用しました。(※本当はPython等のプログラムを組んで出来れば良かったのですが、自身のスキルが及ばず断念しました…(-_-;))
上記のサイトよりGoogle chromeにアドインとしてインストールします。
Pythonを使用するツール「Jupyter notebook」
上記のツールは、Python3を使用する為のツールです。

Pythonを使用するにあたり、私はこの「Jupyter notebook」を使用しておりますが、他のツールでもコードの調整は必要かもしれませんが対応できるかもしれません。
Windowsであればコマンドプロンプトからインストールする事も可能です。今回は「Jupyter notebook」での解説となりますので、宜しくお願い致します。m(_ _)m
それでは下記より各手順毎に解説していきます。
電子書籍ページの保存
手順①
まずは、Amazon Kindle等で購入した本をGoogle Chromeのブラウザで開く。
次に取り込みたいページを開いて、「Alt+Shift+1」でページ全体をFireshotで「画像として保存」をマウスでクリック。

注意
Amazon Kindleではマウスの位置で下図のようなバーが表れ、一緒にキャプチャしてしまうので注意です。
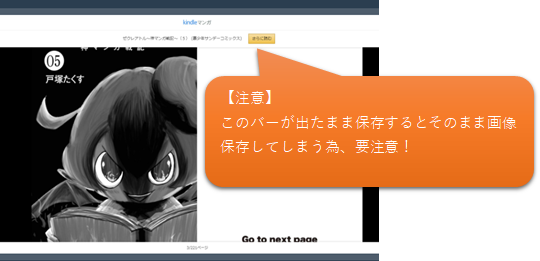
手順②
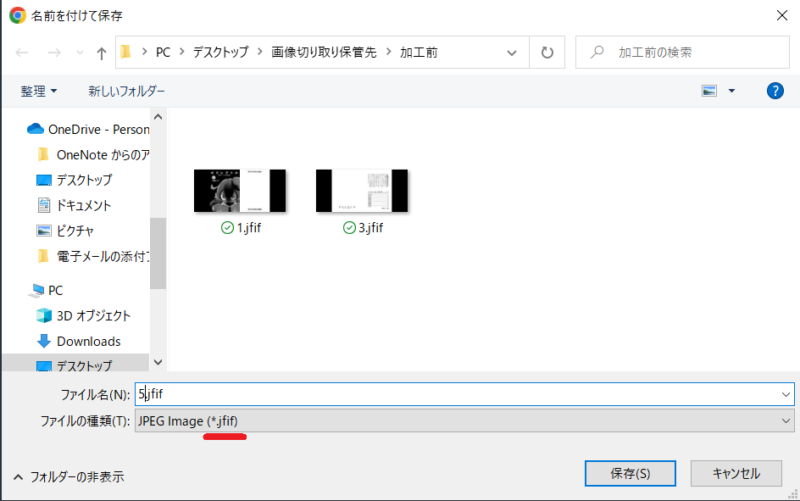
保存画面で、保存先が任意の保存先になっている事を確認。私の場合は、デスクトップに加工前のフォルダを作成してそちらに保存する事にしてます。保存ファイル名は、「1」→「3」→「5」→…の順で保存していきます。(※表紙以外では2ぺージ見開きとなっている為、奇数でカウントしています。)
(※ファイル形式は「.jfif」となり後に画像編集して形式を変更しますが、そのままではperfect Viewerでは見られないので要注意です!)
手順③
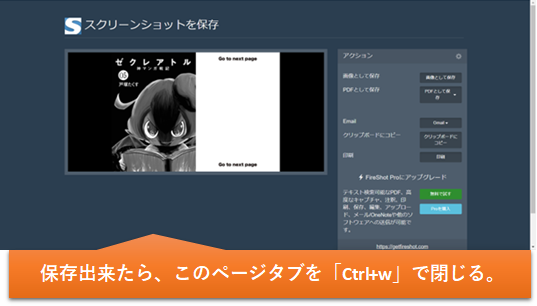
保存出来たら、Fireshotのページタブを「Ctrl+w」で閉じます。Kindleのタブに戻り、「スペースキー」か「↓キー」で次のページに移り、再度①~②を繰り返して、全ページ分を保存します。
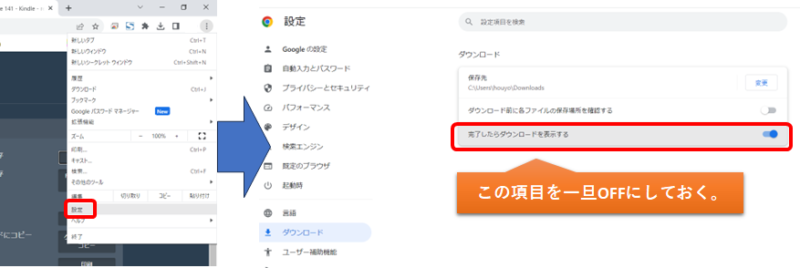
※ダウンロード完了表示をOFFにしたい場合
上記の②で画像保存した時には、下図のようにダウンロード完了のポップアップが毎回出てくる方がいらっしゃるかもしれません。
毎回毎回出てくるので、このポップアップ表示をOFFにしたい時は、右上の![]() アイコンの「Google chromeの設定」より、「設定」>「ダウンロード」>「完了したらダウンロードを表示する」をOFFにしておきます。
アイコンの「Google chromeの設定」より、「設定」>「ダウンロード」>「完了したらダウンロードを表示する」をOFFにしておきます。
保存した画像ファイルをpythonで切取り加工編集
保存した各画像ファイルは、余白が多くまた見開き2ぺージ構成となっている為、これまでScanSnapスキャナで自炊したようにページの切取り加工を行っていきます。

手順④
加工手順前にpython3で画像切り取り加工のコードを作っておく必要があります。まずは「jupyter-notebook」を開き、下記のコードより”Pillow”をインストールします。
pip install Pillow次に下記のコードで画像切り取り加工のコードを作ります。基本は下記のコードをコピー&ペーストして、以下の各★マークの項目で任意の内容に書き換えて下さい。
- ○○へ保存している加工前のフォルダのパスに変更してください。
- △△へ加工後の基本ファイル名に変更してください。([例] ”5巻 ゼクレアトル ~神マンガ戦記~”.jpgのファイル名)
- 開始する追番の数字を入力します。(※1の場合➡「5巻 ゼクレアトル ~神マンガ戦記~_001.jpg」となる)
- 切取りを行う位置範囲を入力します。この位置はwindowsアプリの「
 ペイント」で調べられます。詳細は下の項目で解説したいと思います。
ペイント」で調べられます。詳細は下の項目で解説したいと思います。 - ◇◇へ加工後のフォルダのパスに変更してください。
# 右ページと左ページを切り取るコード
from PIL import Image
import os
# ★1.デスクトップのパス(○○へ保存している加工前のフォルダのパスに変更してください)
desktop_path = "○○"
# ★2.加工後の基本ファイル名 (△△へ加工後の基本ファイル名に変更してください)
kakou_file_name = "△△"
# ★3.開始する追番の数字 (基本ファイル名後の追番開始番号を入力して下さい)
start_sequence_number = 1
# 保存するファイルの数
num_files_to_save = 2
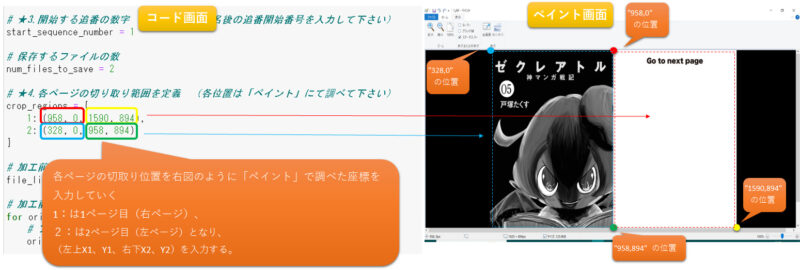
# ★4.各ページの切り取り範囲を定義 (各位置は「ペイント」にて調べて下さい)
crop_regions = {
1: (958, 0, 1590, 894),
2: (328, 0, 958, 894)
}
# 加工前のフォルダ内のファイル一覧を取得
file_list = os.listdir(desktop_path)
# 加工前のフォルダ内のすべてのファイルに対して処理を実行
for original_file_name in file_list:
# ファイルのフルパスを取得
original_file_path = os.path.join(desktop_path, original_file_name)
# 開始する追番の数字を加工前のファイル名から取得
start_sequence_number = int(''.join(filter(str.isdigit, original_file_name)))
if os.path.isfile(original_file_path):
# 画像を開く
image = Image.open(original_file_path)
for i in range(1, num_files_to_save + 1):
# 新しい切り取り範囲を指定して切り取り
if i in crop_regions:
x1, y1, x2, y2 = crop_regions[i]
cropped_image = image.crop((x1, y1, x2, y2))
# 新しいファイル名を設定
new_sequence_number = start_sequence_number + i - 1
new_file_name = f"{kakou_file_name}_{new_sequence_number:03d}.jpg"
# ★5.新しいファイル名の保存先の設定(◇◇へ加工後のフォルダのパスに変更してください)
new_file_path = os.path.expanduser("◇◇")
# ファイルを保存
cropped_image.save(os.path.join(new_file_path, new_file_name))
print(f"新しい切り取った画像を保存しました: {new_file_name}")
else:
print(f"切り取り範囲が定義されていないため、ファイル {original_file_name} をスキップします。")
else:
print(f"加工前のファイル {original_file_name} が見つかりません。")
上記での「★4.各ページの切り取り範囲を定義」については、下図のように1ページ目(右ページ)、2ページ目(左ページ)の各座標点を「ペイント」アプリで調べる事が出来ますので、切り取りたい範囲を設定します。
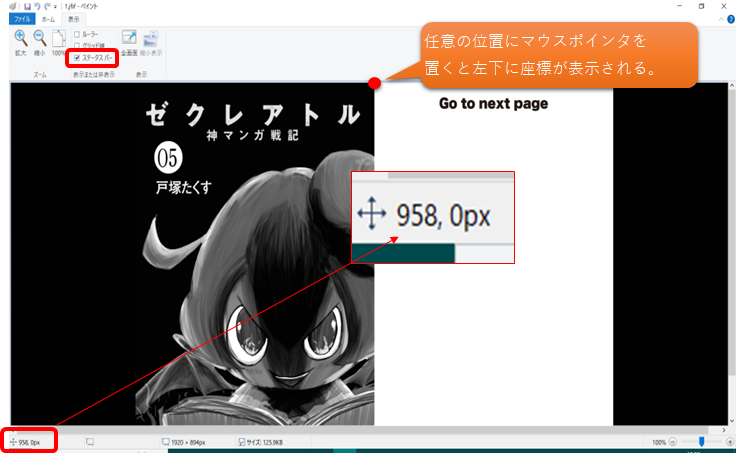
各座標点の調べ方は下図のように「ペイント」にて、任意の位置にマウスポインタを置くと左下に座標が表示されます。(※表示タブにて「ステータス バー」のチェックを入れておきます。)
手順⑤
上記のコード設定が完了しましたら、早速「![]() 」でコードを実行しましょう!
」でコードを実行しましょう!
すると、自動で指定した加工前のフォルダより、加工後のフォルダへ切取り加工とファイル名、拡張子を編集する事が出来ます。かなり楽です。(^^♪
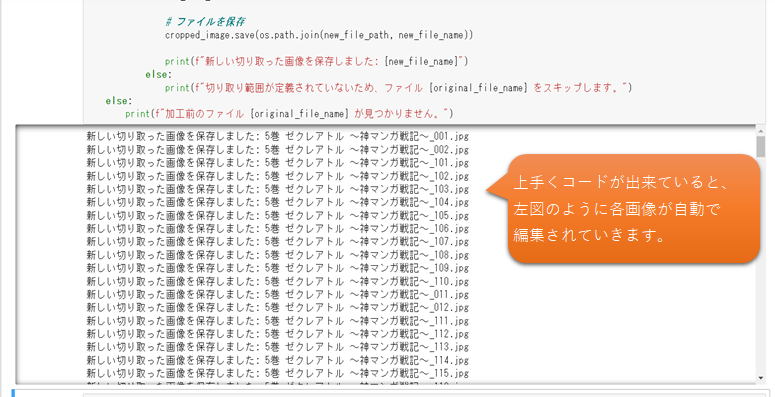
指定した加工後のフォルダに編集されたデータが格納されております。
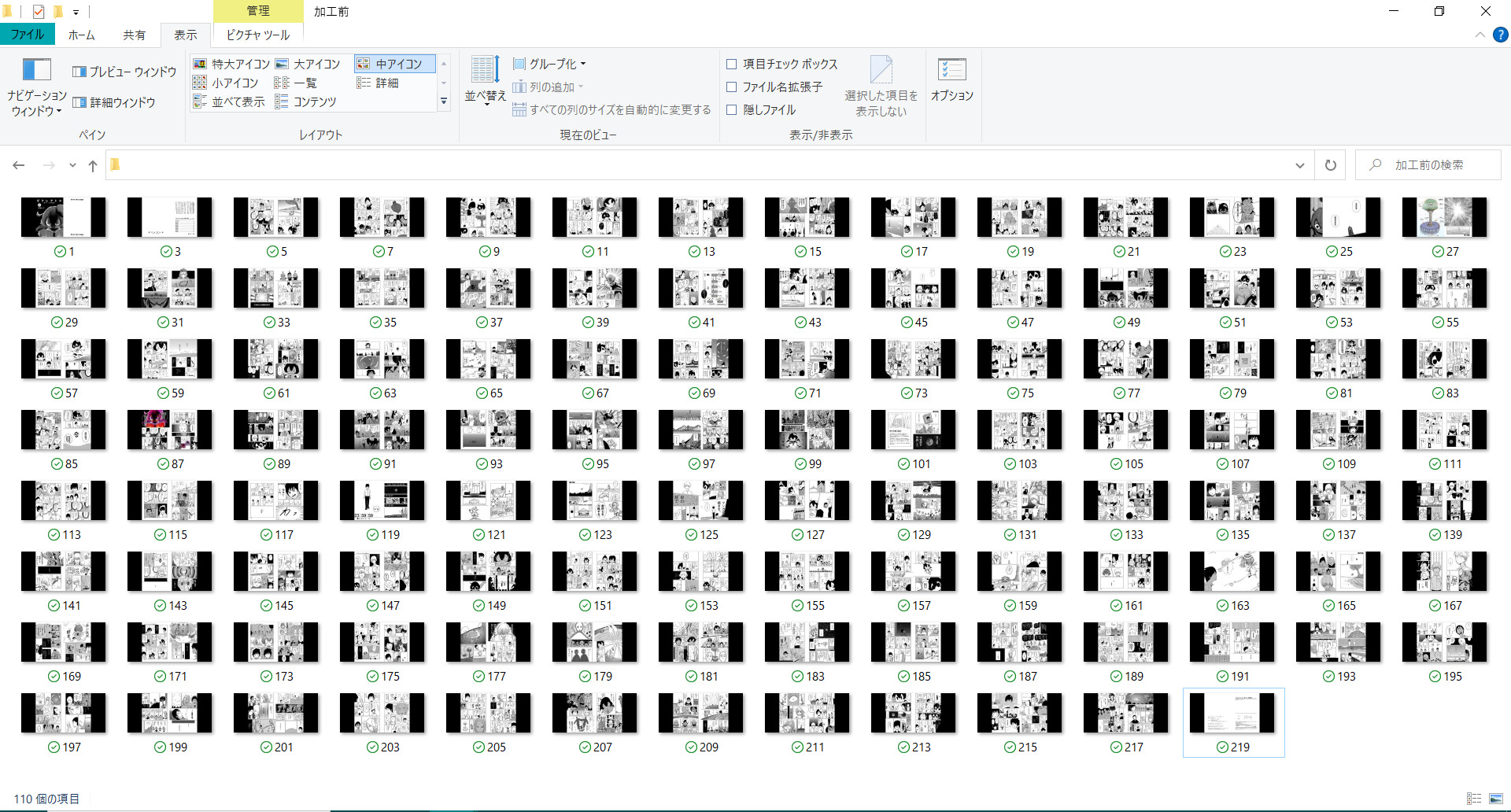
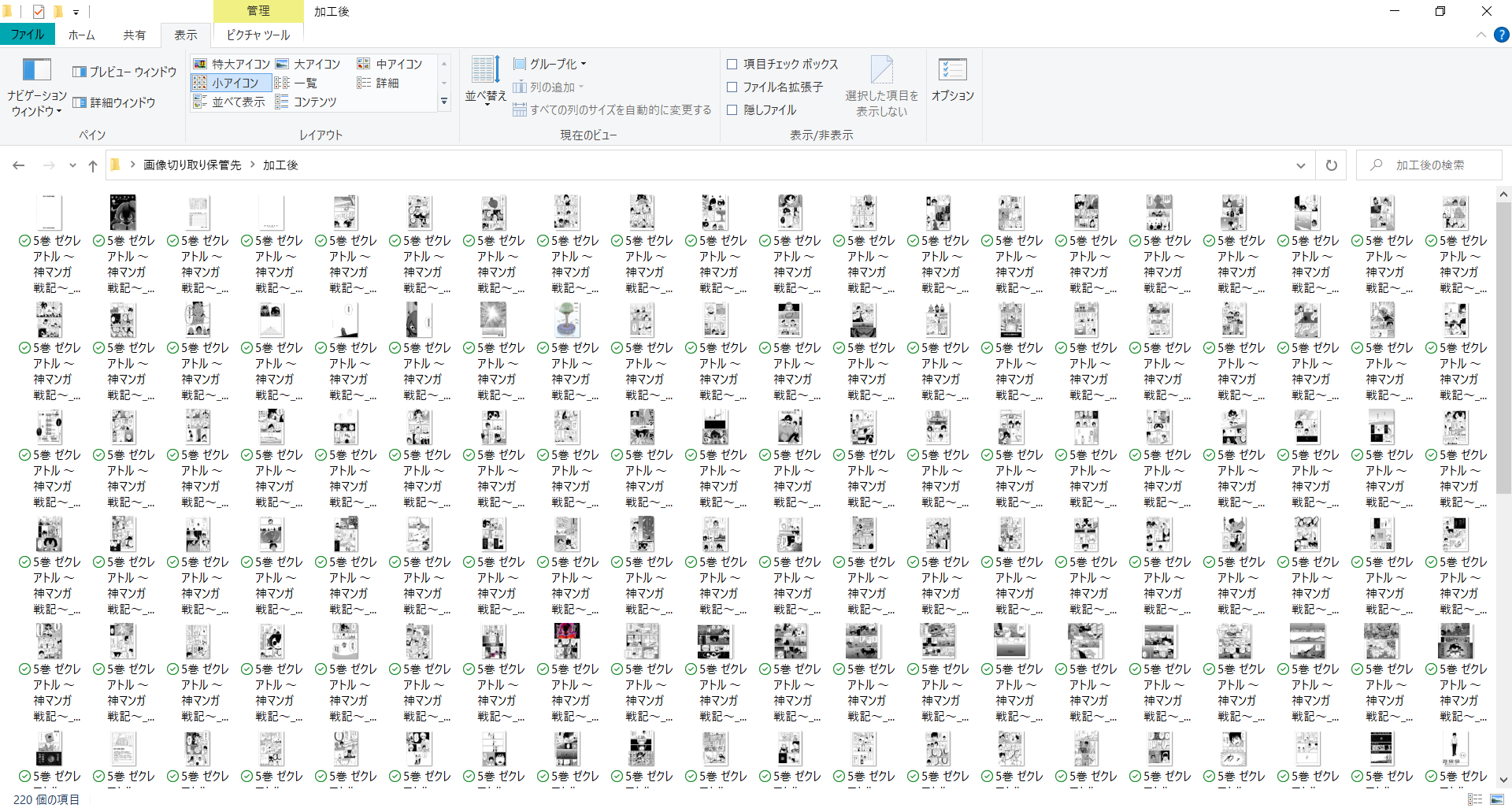
手順⑥
加工後の各画像ファイルを圧縮すれば、完了です!お疲れ様でした ^^) _旦~~
画質編集したい場合は、圧縮前にやっておきましょう。
参考記事

今回は、別途補足編として「電子書籍の自炊」の工程について、解説致しました。
電子書籍しか販売してないと紙媒体では集めにくいですが、上記の方法で電子書籍も自炊化すればこれまでと同様に楽しむことが出来ます。(^^♪
他にも補足的な内容があれば記事にしていきたいと思います ^^) _旦~~
以上
ここまで読んで下さり、誠にありがとうございました。
Special Thanks to YOU!


コメント